Protocolos de red informática
Las redes inalámbricas son aquellas que posibilitan la interconexión de dos o más equipos entre sí sin que intervengan cables, constituyendo así un eficaz medio para la transmisión de cualquier tipo de datos. Las redes inalámbricas se basan en un enlace que utiliza ondas electromagnéticas en lugar de cableado estándar.
Dependiendo del tamaño de la red o de la cobertura que proporciona, se pueden clasificar en los diferentes tipos:
WPAN (Wireless Personal Area Network)
Una red inalámbrica de área personal, incluye redes inalámbricas de corto alcance que abarcan un área de algunas decenas de metros. Este tipo de red se usa generalmente para conectar dispositivos periféricos. Destacan principalmente tecnologías como Bluetooth (IEEE 802.15.1), Zigbee (IEEE 802.15.4) o HomeRF.
WLAN (Wireless Local Area Network)
En las redes de área local, se pueden encontrar tecnologías inalámbricas basadas en HiperLAN como HiperLAN2 o tecnologías basadas en WiFi, que siguen el estándar IEEE 802.11x.
WMAN (Wireless Metropolitan Area Network)
Las WMAN se basan en el estándar IEEE 802.16x o WiMax, así como en LMDS (Local Multipoint Distribution Service).
WWAN (Wireless Wide Area Network)
Las redes inalámbricas de área extensa tienen el alcance más amplio de todas las redes inalámbricas. En estas redes encontramos tecnologías como UMTS (Universal Mobile Telecommunications System), utilizada con los teléfonos móviles de tercera generación (3G) y la tecnología digital para móviles GPRS (General Packet Radio Service).
El comité IEEE 802.11 es el encargado de desarrollar los estándares para las redes de área local inalámbricas. Este estándar, se basa en el mismo marco de estándares que Ethernet, garantizando un excelente nivel de interoperatividad y asegurando una implantación sencilla de las funciones y dispositivos de interconexión Ethernet/WLAN.
En los últimos años las redes de área local inalámbricas han ganando mucha popularidad, ya que permiten a sus usuarios acceder a información y recursos en tiempo real sin necesidad de estar físicamente conectados a un determinado lugar, incrementando en productividad y eficiencia.
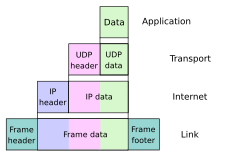
La conexión de redes inalámbricas se restringe a las dos primeras capas del modelo TCP/IP, es decir, el nivel físico y el nivel de enlace, los cuales se explicaran a detalle a continuación. Si además, los elementos de la red soportan enrutamiento o enmascaramiento NAT.
Los tres puntos siguientes, afectan a la capa física.
Número de canal
El número de canal identifica el rango de frecuencias de trabajo. Para redes IEEE 802.11b se usan los canales 1, 7 y 13 en Europa para asegurar suficiente separación de frecuencias y evitar conflictos. Para redes 802.11a no hay riesgo de que los canales se solapen, sólo hay que asegurarse que los nodos cercanos estén operando en canales diferentes. Algunos dispositivos definen automáticamente el canal basado en la frecuencia ociosa escaneando el espectro.
A continuación se muestra el espectro de frecuencias del estándar 802.11b, donde se pueden apreciar los solapamientos entre frecuencias.
Potencia de transmisión
A mayor potencia de transmisión, el punto de acceso tendrá un mayor rango de cobertura, sin embargo, debe evitarse usar más potencia de la necesaria pues aumenta la probabilidad de interferir con otros usuarios. Para muchos países el máximo límite legal es 100 mW, mientras en otros el límite es de 1 W.
Velocidad de transmisión
La tasa de transmisión empleada dependerá del estándar del dispositivo, así para 801.11b el límite superior estará en los 11 Mbps, y para 802.11a y 802.11b en 54 Mbps. En la mayoría de dispositivos, es seleccionable una tasa inferior al límite del estándar.
Los siguientes tres puntos siguientes afectan a la capa de enlace.
Modos de operación o funcionamiento
El estándar 802.11 define dos modos operativos, el modo de infraestructura en el que los clientes de tecnología inalámbrica se conectan a un punto de acceso y el modo ad-hoc en el que los clientes se conectan entre sí sin ningún punto de acceso.
SSID (Service Set IDentifier)
El SSID es el nombre de la LAN inalámbrica. Se trata de una cadena de texto sensible a mayúsculas y minúsculas, que acepta hasta 32 caracteres alfanuméricos y es usada durante el proceso de asociación a una red inalámbrica.
El SSID de un dispositivo se difunde por defecto en las tramas beacon para anunciar su presencia. Esto significa que cualquiera con un adaptador inalámbrico puede ver su red en términos de su SSID. Muchos dispositivos ofrecen la posibilidad de desactivar la difusión del SSID para ocultar la red al público. Este hecho puede mejorar la seguridad de la red inalámbrica.
Control de acceso al medio
Un dispositivo envía tramas beacon periódicamente para difundir su presencia y la información de la red a las estaciones clientes en su radio de cobertura. Las estaciones pueden obtener lista de los dispositivos disponibles buscando estas tramas continuamente en todos canales 802.11. El intervalo de beacon, es la cantidad de tiempo entre la transmisión de tramas beacon de un punto de acceso, su valor por defecto es generalmente 10 ms.
RTS/CTS (Request-To-Send / Clear-To-Send) es el método usado por las redes inalámbricas del estándar IEEE 802.11 acceder al medio y reducir colisiones. RTS/CTS introduce mecanismos para evitar colisiones mediante el método CSMA/CA (Carrier Sense Multiple Access with Collision Avoidance), lo que hace al método de acceso más robusto; pero incrementa el tráfico en la red. Cuando un nodo desea enviar datos, envía una trama RTS, el punto de acceso (AP) la recibe y responde con una trama CTS si el medio está libre. Cuando el nodo recibe el CTS, este comienza a enviar sus datos. Todos los nodos deben ser capaces de escuchar al punto de acceso, la trama CTS alcanzará a todos los nodos conectados a él. La trama CTS incluye un valor del tiempo que los otros nodos deberán esperar para enviar otras tramas RTS.
En esta capa además se llevan a cabo las técnicas de filtrado MAC de acceso al medio, cifrado WEP o WPA y restricciones de acceso por autentificación que se verán en el punto de seguridad.
Protocolo Descripción
802.11 Primer estándar que permite un ancho de banda de 1 a 2 Mbps. Trabaja a 2,4 GHz
802.11a Llamado también WiFi5. Tasa de 54 Mbps. Trabaja entorno a 5 GHz, frecuencia menos saturada que 2,4.
802.11b Conocido como WiFi. El más utilizado actualmente. Las mismas interferencias que para 802.11 ya que trabaja a 2,4 GHz. Tasa de 11 Mbps.
802.11c Es una versión modificada del estándar 802.1d, que permite combinar el 802.1d con dispositivos compatibles 802.11 en el nivel de enlace de datos.
802.11d Este estándar es un complemento del estándar 802.11 que está pensado para permitir el uso internacional de las redes 802.11 locales. Permite que distintos dispositivos intercambien información en rangos de frecuencia según lo que se permite en el país de origen del dispositivo.
802.11e Define los requisitos de ancho de banda y al retardo de transmisión para permitir mejores transmisiones de audio y vídeo. Está destinado a mejorar la calidad del servicio en el nivel de la capa de enlace de datos.
802.11f Su objetivo es lograr la interoperabilidad de puntos de acceso (AP) dentro de una red WLAN mutiproveedor. El estándar define el registro de puntos de acceso dentro de una red y el intercambio de información entre ellos cuando un usuario se traslada desde un punto de acceso a otro.
802.11g Ofrece un ancho de banda de 54 Mbps en el rango de frecuencia de 2,4 GHz. Es compatible con el estándar 802.11b, lo que significa que los dispositivos que admiten el estándar 802.11g también pueden funcionar con el 802.11b.
802.11h El objetivo es que 802.11 cumpla los reglamentos europeos para redes WLAN a 5 GHz. Los reglamentos europeos para la banda de 5 GHz requieren que los productos tengan control de la potencia de transmisión y selección de frecuencia dinámica.
802.11i Aprobada en Julio 2004, se implementa en WPA2. Destinado a mejorar la seguridad en la transferencia de datos (al administrar y distribuir claves, y al implementar el cifrado y la autenticación). Este estándar se basa en el protocolo de encriptación AES.
802.11n Se basa en la tecnología MIMO. Trabajará en la frecuencia de 2.4 y 5 GHz. Soportará tasas superiores a los 100Mbps.
802.11s Redes Mesh o malladas.
Profundizando un poco más, a continuación se muestran las características más importantes de los principales protocolos.
Protocolo
Fecha de Aprobación
Frecuencia (GHz)
Modulación
Throughput (Mbps)
Rango (Indoor)
Real
Teórico
802.11a
1999
5.15-5.355.47-5.7255.725-5.825
OFDM con BPSK, SPSK y 16/64 QAM
25
54
~50
802.11b
1999
2.4-2.5
CCK y DSSS(5 y 11 Mbps), DQPSK (2 Mbps), DBPSK (1Mbps)
6.5
11
~100
802.11g
2003
2.4-2.5
DSSS, DQPSK, DBPSK.
OFDM con BPSK, SPSK y 16/64 QAM
25
54
~100
Los dispositivos IEEE 802.11a transmiten a 5 GHz dando cobertura a células de RF más pequeñas con un coste energético superior, visto de otra manera, se necesitaran más puntos de acceso 802.11a para cubrir la misma zona que con b. Por contra, el adoptar la banda de frecuencia de 5 GHz y utilizar la modulación OFDM hacen que 802.11a goce de dos notables ventajas respecto al 802.11b, aumenta la tasa de transmisión de 11 Mbps a 54 Mbps y aumenta el número de canales sin solapamiento, pudiendo así admitir un mayor número de usuarios. Está tecnología presenta el inconveniente de no ser compatible con 802.11b.
El 802.11g opera en la misma banda de frecuencia que el 802.11b de 2.4 GHz y con los mismos tipos de modulación DSSS a velocidades de hasta 11 Mbps, mientras que a velocidades superiores utiliza tipos de modulación OFDM más eficientes. Es un estándar compatible con los equipos 802.11b ya existentes.
En comparación con el estándar IEEE 802.11a, el 802.11g tiene un ancho de banda utilizable más bajo, lo que implica un menor número de usuarios. Aunque las modulaciones OFDM permiten una velocidad más alta, el ancho de banda disponible total en la banda de frecuencia de 2,4 GHz no varía. El motivo es que el IEEE 802.11g todavía está restringido a tres canales en la banda de 2,4 GHz.
Modos de funcionamiento
El estándar 802.11 define dos modos operativos, el modo de infraestructura en el que los clientes de tecnología inalámbrica se conectan a un punto de acceso y el modo ad-hoc en el que los clientes se conectan entre sí sin ningún punto de acceso
- Modo ad hoc
En redes IEEE 802.11, el modo ad hoc se denota como Conjunto de Servicios Básicos Independientes (IBSS, Independent Basic Service Set). El modo ad hoc, también conocido como punto a punto, es un método para que clientes inalámbricos puedan establecer una comunicación directa entre sí, no siendo necesario involucrar un punto de acceso central. Todos los nodos de una red ad hoc se pueden comunicar directamente con otros clientes. Cada cliente inalámbrico en una red ad hoc debería configurar su adaptador inalámbrico en modo ad hoc y usar los mismos SSID y número de canal de la red. Este tipo de redes normalmente está formado por un pequeño grupo de dispositivos dispuestos cerca unos de otros, siendo su rendimiento menor a medida que el número de nodos crece.
Configuración
Nodo 1
Nodo 2
Modo
Ad hoc
SSID
El mismo
Canal
El mismo
IP
IPA (normalmente fija)
IPB (normalmente fija)
En una red ad hoc, el rango del BSS está determinado por el rango de cada estación, por lo que si dos estaciones de la red están fuera de rango la una de la otra, no podrán comunicarse aún cuando puedan ver otras estaciones. A diferencia del modo infraestructura, el modo ad hoc no tiene un sistema de distribución que pueda enviar tramas de datos desde una estación a la otra.
- Modo infraestructura
En el modo de infraestructura (BSS, Basic Service Set), cada estación se conecta a un punto de acceso a través de un enlace inalámbrico. La configuración formada por el punto de acceso y las estaciones ubicadas dentro del área de cobertura se llama conjunto de servicio básico o BSS. Estos forman una célula y se identifica a través de un BSSID, que corresponde con la dirección MAC del punto de acceso.
Es posible vincular varios puntos de acceso juntos para formar un conjunto de servicio extendido o ESS (Extended Service Set). El sistema de distribución también puede ser una red conectada, un cable entre dos puntos de acceso o incluso una red inalámbrica. El ESSID, a menudo es abreviado por SSID, que no es más que el nombre de la red. A continuación se muestra la configuración típica del modo infraestructura.
Configuración
Punto de Acceso
Usuarios
Modo
Infraestructura
SSID
Debe definir un SSID
Conectar al SSID
Canal
Debe definir canal
Descubrir el canal
IP
Normalmente servidor DHCP
Asignado por DHCP
La limitación de este modo, es en cuanto al número máximo de clientes inalámbricos que se pueden conectar manteniendo una determinada calidad de servicio. Un AP (Access Point) proporciona normalmente un alcance de entre 20 m a 100 m en interiores. En exteriores, los alcances son muy superiores, pudiéndose alcanzar distancias superiores a 200 m dependiendo de la ganancia de la antena y la potencia emitida. Los clientes inalámbricos pueden acceder dentro del rango de cobertura que proporcione el AP.
Los puntos de acceso se comunican entre sí con el fin de intercambiar información sobre las estaciones, así cuando un usuario se mueve desde un BSS a otro dentro de un ESS, el adaptador inalámbrico de su equipo puede cambiarse de punto de acceso dependiendo la calidad de la señal que reciba o la saturación del nodo, permitiendo al cliente inalámbrico moverse de forma transparente de un punto de acceso a otro. Esta característica es conocida como itinerancia.
Normalmente, en una configuración típica como se muestra en la Figura 8, uno de los AP se conecta a una red cableada con acceso a Internet, por el que fluirá todo el tráfico que requiera una estación o red no alcanzable por los AP.
Seguridad.
Este punto es fundamental, ya que las redes inalámbricas usan ondas de radio y son más susceptibles de ser interceptadas, es decir, no brindan la protección y privacidad de un cable, por lo que se hace casi indispensable proveer de mecanismos de seguridad a nivel de enlace que garanticen la integridad y confiabilidad de los datos, en definitiva se busca asegurar que la información transmitida entre los puntos de acceso y los clientes no sea revelada a personas no autorizadas. En este punto, también se tratarán los mecanismos de autenticación y control de acceso, como medida de seguridad diseñada para establecer la validez de una transmisión.
A continuación se explica brevemente en que consisten los principales mecanismos que intentan o ayudan a garantizar la privacidad, integridad y confidencialidad de la transmisión, ellos son WEP, WPA, filtrado MAC y 802.1x [WEB09].
Mecanismo de seguridad WEP (Wired Equivalent Privacy) obsoleto
La confidencialidad en redes inalámbricas ha sido asociada tradicionalmente con el término WEP, que forma parte del estándar IEEE 802.11 original, de 1999. Su propósito fue brindar un nivel de seguridad comparable al de las redes alambradas tradicionales.
Se trata de un mecanismo basado en el algoritmo de cifrado RC4, y que utiliza el algoritmo de chequeo de integridad CRC (Chequeo de Redundancia Cíclica). Un mal diseño del protocolo provoco que al poco tiempo de ser publicado quedara obsoleto. Actualmente existen varios ataques y programas para quebrar el WEP tales como Airsnort, Wepcrack, Kismac o Aircrack. Algunos de los ataques se basan en la limitación numérica de los vectores de inicialización del algoritmo de cifrado RC4, o la presencia de la llamada “debilidad IV” en un datagrama. Este mecanismo no es recomendado para garantizar la seguridad de una red.
WPA y WPA2
En 2003 se propone el Acceso Protegido a redes WiFi o WPA y luego queda certificado como parte del estándar IEEE 802.11i, con el nombre de WPA2 en 2004.
WPA y WPA2 pueden trabajar con y sin un servidor de distribución de llaves. Si no se usa un servidor de llaves, todas las estaciones de la red usan una llave de tipo PSK (Pre-Shared-Key), en caso contrario se usa habitualmente un servidor IEEE 802.1x.
La versión certificada de WPA incluye dos cambios principales que aumentan considerablemente la seguridad, se reemplaza el algoritmo Michael por un código de autenticación conocido como el protocolo CCMP (Counter-Mode/CBC-Mac) considerado criptográficamente seguro y se reemplaza el algoritmo RC4 por el AES (Advanced Encryption Standard) o Rijndael. WPA2 bien configurado, es actualmente el mecanismo más seguro en que se puede confiar.
Filtrado MAC
Es un mecanismo que realizan los puntos de acceso que permite únicamente acceder a la red a aquellos dispositivos cuya dirección física MAC sea una de las especificadas. El mecanismo se puede utilizar como control adicional; pero es fácilmente vulnerable aplicando un clonado de la MAC a suplantar.
Detener la difusión de la SSID como medida de seguridad
Se pueden configurar los puntos de accesos para que no difundan periódicamente las llamadas Tramas Baliza o Beacon Frames, con la información del SSID. Evitar esta publicación implica que los clientes de la red inalámbrica necesitan saber de manera previa que SSID deben asociar con un punto de acceso; pero no impedirá que una persona interesada encuentre la SSID de la red mediante captura de tráfico. Este sistema debe considerarse tan solo como una precaución adicional más que una medida de seguridad.
Protocolo 802.11x
Este protocolo ofrece un marco para autentificar y controlar el acceso a los puntos de accesos. Sirve como soporte para implementaciones de seguridad sobre servidores de autentificación. El funcionamiento se puede ver en la Figura 9 y es básicamente el siguiente, el cliente envía una petición al servidor de autentificación a través del AP, quien comprueba el certificado o el nombre de usuario y contraseña utilizando esquemas de autentificación como EAP encargados de la negociación. Si es aceptado, el servidor autorizará el acceso al sistema y el AP permite el acceso asignando los recursos de red.